Métodos baseados em Hidden Markov Models (HMMs), ou Modelos Ocultos de Markov, são métodos estocásticos, que consistem na geração de modelos de classes acústicas, que fazem uso de informações temporais, o que pode ser bastante útil para algumas aplicações, como é o caso dos sistemas de reconhecimento dependentes de texto, como já apresentado.
Os HMMs podem modelar uma unidade menor da palavra (como os fonemas ou mesmo fonemas inseridos em contextros diferentes, como difones ou trifones), uma palavra, ou ainda uma frase inteira.
Os HMMs podem ser vistos como máquinas de estado finitas, onde a cada unidade de tempo, ocorre uma transição de estados e, a cada estado, emite-se um vetor acústico com uma função densidade de probabilidade associada. Ou seja, em cada estado, um GMM é usado para caracterizar um vetor acústico observado. Um modelo λ pode ser escrito como na equação 4.2.1.
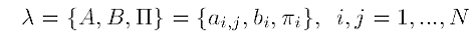
, onde:
- A = { aij } representa a matriz de todas as probabilidades de transições entre um estado i e outro j;
- B = { bi } representa a matriz de todas as probabilidades de emissão de saída em um determinado estado i, ou seja, a probabilidade de se emitir determinado vetor acústico naquele estado;
- Π = { πi } representa a matriz com as probabilidades de um modelo ser iniciado a partir de um estado i.
A figura abaixo representa, então, um HMM com três estados emissores, onde são adicionados ainda dois estados não emissores no início e no fim do modelo para fins de facilitar a união entre modelos. Na figura, xt representa um dado vetor acústico emitido em uma unidade de tempo t.
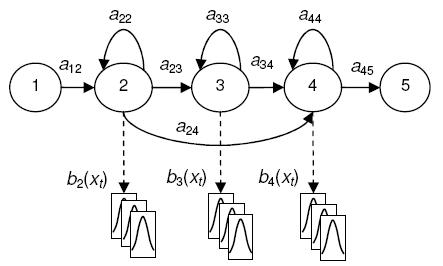
.

O objetivo da modelagem, assim como nos métodos baseados em GMMs, é achar o ajuste dos parâmetros do modelo que maximize a verossimilhança.
Além de todos os parâmetros presentes na mistura de gaussianas associada a cada estado, as matrizes de transição de estados também são consideradas como parâmetros do modelo.
Uma vez que, através do modelo, não é possível saber a sequência de estados, considera-se uma sequência de estados fixa e calcula-se a probabilidade a priori, considerando-se todas as possíveis sequências de estados, da seguinte maneira:
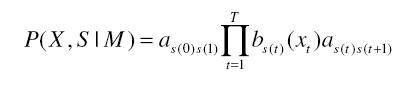

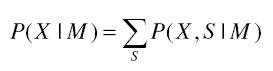

, onde:
- X é uma sequência de vetores acústicos;
- S é uma sequência de estados
- M é um modelo;
- as(0)s(1) é a probabilidade de começar em um estado s(1);
- bs(t) (xt) é a probabilidade de emissão de um vetor xt no estado s(t) e unidade de tempo t;
- as(t)s(t+1) é a probabildade de transição de um estado no tempo t para outro, no tempo t+1.
Na fase de teste, o objetivo, então, é achar a melhor sequência de estados, que maximize a probabilidade a posteriori. Para tal, faz-se uso de um algoritmo conhecido como algoritmo de Viterbi, que consiste em um algoritmo de busca síncrono, que procura a o estado mais provável a cada unidade de tempo.
 Top
Top