Um Gaussian mixture model (GMM), ou modelo de misturas de gaussianas é um modelo estocástico, que modela classes - que, para o reconhecimento de locutor, podem ser unidades acústicas ou mesmo um locutor - sem que se considerem informações temporais.
O objeto de interesse de um problema de classificação é o cálculo da chamada probabilidade a posteriori, que pode ser calculada através da fórmula de Bayes, como mostrado na equação 4.1.1.
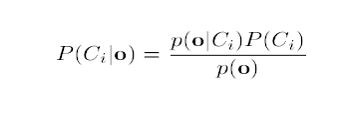
, onde:
- Ci representa uma classe (Para um modelo com um total de M classes, i = 1...M);
- o representa uma observação (vetor acústico observado);
- p(o| Ci) é a chamada probababilidade condicional;
- P(Ci) é a chamada probabilidade a priori.
Uma vez que, para fins de reconhecimento de locutor, o elemento observado não corresponde a um único elemento e sim a uma sequência de vetores acústicos, então, para uma sequência de T vetores, considerando a ocorrência de cada observação como um evento independente, podemos construir uma regra de decisão para o problema através da maximização da probabilidade a posteriori, como mostrado na equação 4.1.2. Nesta equação, ainda é possível notar a ausência do termo presente no denominador da equação 4.1.1. A ausência deste termo é justificável, uma vez que ele será o mesmo para todas as classes testadas.
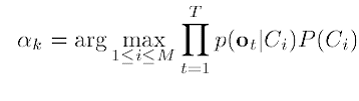
A decisão é feita, então, baseando-se nas funções densidade de probabilidade (fdps) dos vetores acústicos. A função da etapa da modelagem em um sistema de reconhecimento de locutor é a de prover uma estimação a priori dessas fdps. Isso é feito através de um algoritmo de re-estimação de parâmetros. Dentre eles, o mais usado é o algoritmo de Baum-Welch, também conhecido como Forward-Backward algorithm ou algoritmo de avanço-retorno. Através desse algoritmo, é possível então, estimar os parâmetros de médias, variâncias e pesos das misturas de gaussianas para cada fdp.
Os modelos GMMs podem ser, então, definidos como na equação 4.1.3.
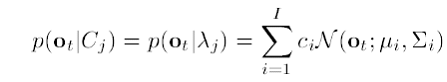

, onde a probabilidade condicional p(ot| Cj) é substituída por p(ot| λj) - onde λj é um modelo GMM para a classe Cj - e é, então, escrita como uma mistura de gaussianas multivariadas, onde ci representa o peso de cada gaussiana na mistura e N (ot ; µi ; Σi) representa uma gaussiana multivariada, com vetores de médias e variâncias µi e Σi , respectivamente.
O modelo fornecerá, então, a chamada probabilidade condicional, que é calculada como na equação 4.1.3 e que será usada no processo de decisão apresentado na equação 4.1.2. Neste caso, a chamada probabilidade a priori representa a frequência com que cada classe Ci aparece na base de dados e supõe-se que ela seja conhecida.
 Top
Top