Para que seja possível processar o sinal de fala para geração do sistema de reconhecimento de locutor, torna-se necessária, em uma primeira etapa, a conversão da onda sonora em um sinal digital, que pode ser compreendido pelo computador. O processamento do sinal de fala, então, consistirá na amostragem do sinal e na extração de parâmetros do mesmo que serão relevantes para o processo de reconhecimento de locutor.
Existem alguns métodos para modelar o sinal de voz, como o método de predição linear Linear Predictive Coding (LPC), que é um método rápido, simples e também bastante efetivo na extração dos parâmetros principais do sinal.
No método LPC, uma amostra de sinal sn, como representado na equação 2.2.1, é modelada através da combinação linear de p amostras anteriores.
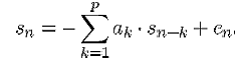
, onde:
- p é a ordem de predição;
- ak são os chamados coeficientes de predição;
- sn-k são as saídas anteriores;
- cn é o erro de predição.
O objetivo, então, é estimar os coeficientes de predição ak, de modo a minimizar o erro de predição cn. Os chamados vetores de características do sinal são obtidos através da estimação desses coeficientes e estes são geralmente transformados de forma não linear em domínios perceptuais significativos para a aplicação em questão.
No entanto, um método de extração de coeficientes mel-cepstrais do sinal, que não envolve análise de predição linear, é o mais usado em sistemas de reconhecimento de locutor, uma vez que demonstrou-se que este método apresentava bom desempenho tanto para sistemas de reconhecimento de locutor quanto para sistemas de reconhecimento de voz.
Os Mel-Frequency Cepstrum Coefficients (MFCCs) ou coeficientes mel-cepstrais podem ser definidos como coeficientes derivados de um tipo de representação cepstral do sinal. O cepstro pode ser visto como o espectro de um espectro. Neste caso, uma escala logaritmica é usada para posicionar as bandas de frequência (ou seja, a escala de frequência é transformada para dar menos ênfase a frequências altas), o que aproxima o modelo do comportamento do sistema auditivo humano, uma vez que a percepção das frequências dos sons por seres humanos é dita não-linear.
Em sistemas de reconhecimento de locutor, também é comum a extração de coeficientes derivativos dos coeficientes mel-cepstrais no tempo, de modo a mapear características adicionais do sinal. Estes coeficientes são também conhecidos por coeficientes delta-cepstrais.
É importante mencionar ainda que as densidades dos cepstros são facilmente modeladas através de modelos de misturas de gaussianas (GMMs), apresentados na seção 4 deste trabalho.
Além disso, também se torna interessante a extração dos logarítimos das frequências fundamentrais do sinal, assim como os derivativos desses valores no tempo para a formação dos vetores de características que representarão matematicamente o sinal de voz.
Como já mencionado na seção anterior, as frequências fundamentais (frequências de vibração das cordas vocais) correspondem a características possíveis de serem consideradas na ocasião da distinção entre locutores.
 Top
Top