1 - Introduçăo
2 - Biometria
3 - O som e a voz
4 - Conversăo do som em sinal digital
5 - Reconhecimento de locutor
6 - Conclusőes
7 - Perguntas
8 - Bibliografia
O trabalho seguinte ao da digitalizaçăo do sinal é o de reconhecimento do locutor. Tais sistemas funcionam em duas etapas como mostrado na Figura 3, conhecidas como treino e teste. Na primeira etapa, o locutor fornece as amostras para a base de dados, para que estas possam servir como parâmetro futuramente. Ou seja, essas amostras servem para criar um modelo dependente do locutor em questăo e guardá-lo na base de dados. Na segunda etapa, o locutor irá tentar o acesso ao sistema. Ao fazę-lo, ele pede para usar o sistema, e o sistema pede que o usuário entre com uma elocuçăo (uma senha, por exemplo). Essa elocuçăo será processada e comparada com o modelo guardado na base de dados, e será fornecido uma pontuaçăo (score) baseada no quăo similar ao modelo foi a elocuçăo. Após essa etapa, compara-se essa pontuaçăo com a mínima aceita pelo sistema. Se for maior ou igual que esse valor, o acesso é garantido.
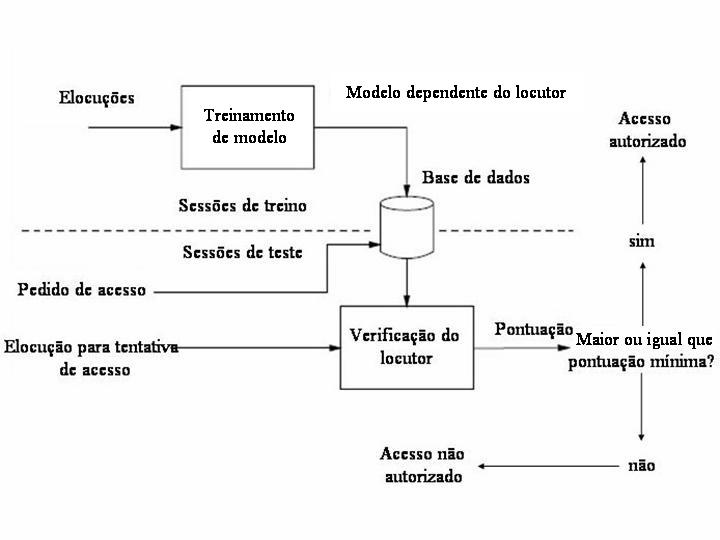
Há dois tipos de sistema de reconhecimento de locutor: os dependentes de texto e os independentes de texto. Nos sistemas dependentes de texto, as elocuçőes săo as mesmas para treino e para teste. No entanto, há uma restriçăo: a locuçăo de entrada deve corresponder ŕ uma série de palavras que se encontram na base de dados do sistema, de tal forma que năo importa tanto a pessoa que está falando, desde que ela fale as palavras corretas, como uma senha, por exemplo. Nos sistemas independentes de texto, como o da Figura 3, o acesso ao sistema năo é baseado em palavras guardadas na base de dados, e sim em características da voz da pessoa. Esses sistemas, no entanto, exigem mais elocuçőes para treiná-los, de forma a garantir uma boa precisăo.
Para sistemas dependentes de texto, o modelo mais utilizado é o HMM (Hidden Markov Models), que se baseia em observar as elocuçőes de treino e teste em um instante de tempo, e verificar a semelhança entre as duas do início ao fim das mesmas, através dos parâmetros espectrais de cada uma delas. Tal método se baseia, ainda, em variaçőes estatísticas.
Para sistemas independentes de texto, o modelo mais utilizado é o GMM (Gaussian Mixture Models), que se assemelha muito ao HMM por também se basear em princípios estatísticos, sem, no entanto, observar as elocuçőes em instantes de tempo.
| <<Anterior |  Topo Topo |
Próxima>> |