1 - Introduçăo
2 - Biometria
3 - O som e a voz
4 - Conversăo do som em sinal digital
5 - Reconhecimento de locutor
6 - Conclusőes
7 - Perguntas
8 - Bibliografia
O HMM funciona comparando elocuçőes com palavras, com sub-unidades de palavras (fonemas, por exemplo) ou com unidades maiores (frases inteiras, por exemplo). Ele é uma máquina de estados, na qual cada estado contém a informaçăo que aquele HMM traz. Também é composto por matrizes de transiçăo, que contęm a probabilidade de cada passagem de um determinado estado para um outro estado. Essa probabilidade é usualmente modelada segundo a distribuiçăo normal. A cada estado emissor, um vetor acústico é emitido.
Cada estado pode ser entendido como uma das unidades supracitadas, como palavras, fonemas etc. Um HMM com tręs estados pode ser visto na Figura 4.
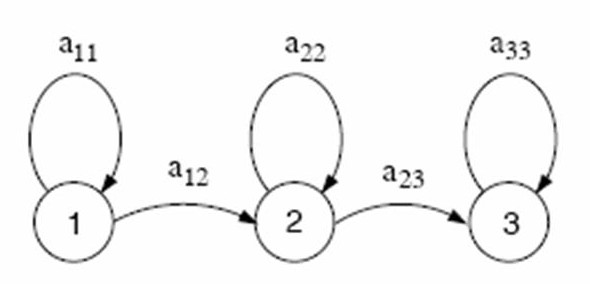
Ou seja, o HMM modela a seqüęncia temporal de cada elocuçăo através da emissăo de vetores acústicos. No entanto, năo é possível conhecer inicialmente qual seqüęncia de estados será descrita. Para resolver esse problema, considera-se todas as seqüęncias de estados, calculando a probabilidade de ocorręncia de cada uma delas, pela fórmula:
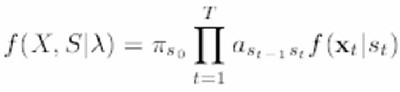
Na qual X é o conjunto de vetores acústicos, l é o modelo em questăo, S săo os estados, ps0 é a probabilidade do estado s0 ser o inicial, as(t-1)s(t) é a probabilidade de, partindo de um estado no tempo t-1 se chegar a um estado no tempo t, e f(xt|st) é a probabilidade condicionada de se emitir um vetor xt dado que se está no estado st. Com essa fórmula é possível calcular o estado mais provável de ocorrer a cada instante de tempo. Por fim, sendo um HMM ou GMM, o sistema verifica se irá aceitar ou năo o acesso, através da comparaçăo com o modelo da base de dados.
| <<Anterior |  Topo Topo |
Próxima>> |