Verificaçăo Dinâmica da Assinatura
Uma vez coletadas as amostras de assinaturas, por meios de dispositivos de captura como tablets ou PDAs, as informaçőes obtidas a partir da caneta utilizada nesses aparelhos săo armazenadas como um conjunto de vetores ao longo do tempo.
Pode-se utilizar duas ou mais assinaturas originais de um indivíduo como a base de geraçăo de dados. Essas assinaturas originais săo coletadas e armazenadas em uma série de vetores baseados em amostras temporais da caneta. As amostras podem compreender dados como: tempo, posiçőes x e y da caneta, indicador binário (que diz se a caneta está sobre o tablet), pressăo contínua da caneta, azimute e altitude da caneta (Rabasse et al., 2007).
A Figura 5 mostra uma assinatura digitalizada e algumas informaçőes dinâmicas associadas. Ambas obtidas através de um dispositivo gráfico.
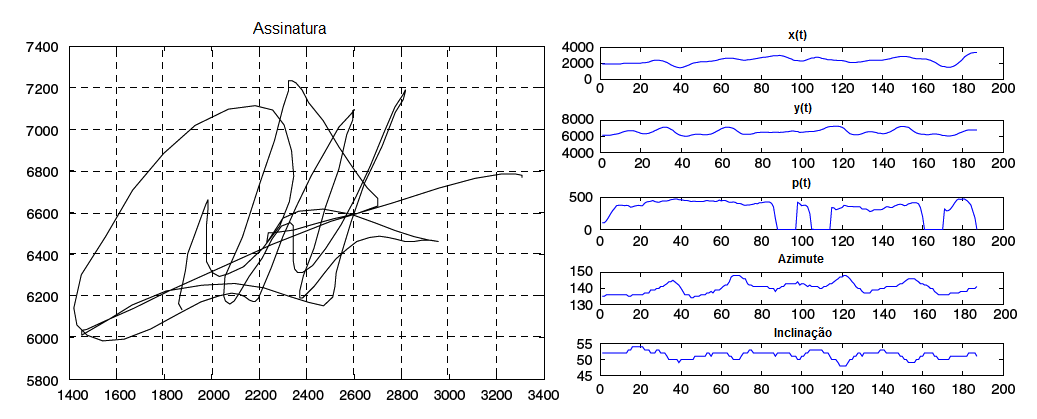
Figura 5: Exemplo de uma assinatura e suas informaçőes que podem ser obtidas dinamicamente. Adaptada de (Faundez-Zanuy, 2007)
Topo
Pré-processamento
O sinal de entrada obtido a partir de um dispositivo ou de uma caneta digitalizadora pode ser muito irregular. Isso pode acontecer porque o espaço físico oferecido para a escrita da assinatura normalmente varia entre diferentes aparelhos ou até mesmo a caneta utilizada pode alterar a suavizaçăo e afetar o tamanho da assinatura. Por meio do uso de um método baseado em um filtro Gaussiano, é possível suavizar a assinatura (Jain et al., 2002).
Para que se possa comparar características espaciais de uma assinatura, a representaçăo năo deve conter dependęncias de tempo. Para eliminar essas dependęncias, realiza-se a reamostragem da assinatura de modo uniforme, com um espaçamento equidistante. Alguns trechos da assinatura carregam informaçőes importantes e săo chamados pontos críticos, como exemplo pode-se citar os pontos onde a trajetória sofre mudanças e o ponto de início e final de um traço. Antes do pré-processamento, é feita a extraçăo desses pontos e sua posiçăo é armazenada durante os processos de reamostragem e de suavizaçăo. Outras características que devem ser extraídas antes da reamostragem săo as relacionadas ao tempo. Estas săo, entăo, propagadas para os pontos obtidos na reamostragem por meio de interpolaçăo (Jain et al., 2002).
O resultado deste processo pode ser visto na Figura 6.
Figura 6: Etapa de pré-processamento.
(a) Imagem de uma assinatura antes do pré-processamento. Os pontos de amostragem săo espaçados igualmente no tempo.
(b) Imagem da assinatura (a) após passar pela etapa de pré-processamento. Nota-se que os traços foram concatenados e que a assinatura sofreu suavizaçăo. Extraída de (Jain et al., 2002)
Topo
Extraçăo de parâmetros
Uma vez que, todos os traços tenham sido concatenados durante o pré-processamento, o número original de traços é armazenado para ser usado como uma característica global (Jain et al., 2002). A partir da imagem pré-processada, săo obtidas características locais que podem ser divididas em duas categorias:
Características estáticas: Correspondem aos parâmetros extraídos enquanto um indivíduo assina. Săo grandezas como o máximo, o mínimo e a média da velocidade usada na escrita, medidas de curvatura, comprimento de segmentos, dentre outras. O agrupamento de todas essas características corresponde a um vetor N-dimensional, onde N é o número de medidas (Faundez-Zanuy, 2007).
Características dinâmicas: Săo baseadas na evoluçăo de parâmetros ao longo do tempo, portanto, podem ser representados como funçőes temporais f(t). Segundo Faundez-Zanuy (2007), como exemplos dessas características, tem-se as posiçőes x(t) e y(t), velocidade v(t), aceleraçăo a(t), pressăo p(t), aceleraçăo tangencial, raio de curvatura, aceleraçăo normal e outras (uma amostra desses parâmetros pode ser vista na Figura 3). A etapa de extraçăo de características dinâmicas é quase inexistente, por outro lado, há um alto nível de dificuldade no passo de comparaçăo.
Pode-se calcular os valores para a velocidade e aceleraçăo instantâneas conforme os dados iniciais săo gerados e/ou lidos dos arquivos pertencentes a cada pessoa, enquanto ela escreve, da seguinte forma, proposta por Rabasse et al. (2007):
Sejam:
N = o número de pontos em uma assinatura;
xi e yi = posiçőes x e y, respectivamente;
ti = a amostra de tempo para o i-ésimo ponto de uma assinatura.
Assim, teremos:

Estas duas características (aceleraçăo e velocidade), associadas ŕs mediçőes iniciais geradas a partir do dispositivo eletrônico utilizado, servem como parâmetros ao método de verificaçăo dinâmica de assinatura.
Dentre as características relacionadas ŕ assinatura de cada indivíduo, algumas săo mais importantes que outras, pois permitem a autenticaçăo com maior acurácia. Por este motivo, é necessário fazer uma seleçăo dos parâmetros extraídos.
TopoComparaçăo
A comparaçăo de assinaturas tem por finalidade medir a similaridade entre as características locais da assinatura que se quer analisar e o modelo. Desta forma, deve-se escolher um método para realizar as comparaçőes. De acordo com Faundez-Zanuy (2007), as quatro abordagens mais conhecidas para reconhecimento de padrőes săo: comparaçăo de modelos, classificaçăo estatística, comparaçăo sintática ou estrutural e redes neurais. Esses métodos geralmente năo săo utilizados de forma independente e podem existir diferentes interpretaçőes para o mesmo modelo de reconhecimento de padrőes.
Comparaçăo de Modelos
Cada assinatura pode ser descrita como um conjunto das características extraídas de uma determinada posiçăo da amostra (Jain et al., 2002). Essas características podem ser representadas na forma de um vetor, cujo tamanho é o número de características locais extraídas, e comparadas através de uma medida de distância.
Um método de comparaçăo de modelos frequentemente utilizado é o Dynamic Time Warping – DTW. Este método utiliza uma estratégia de programaçăo dinâmica que faz o gerenciamento de variaçőes de tamanho entre as assinaturas de entrada e as assinaturas de referęncia (Faundez-Zanuy, 2007). O DTW encontra um alinhamento entre pontos nos vetores tais que a soma da diferença entre cada par de pontos alinhados seja mínimo. Para encontrar a diferença mínima, todos os possíveis alinhamentos devem ser analisados (Jain et al., 2002).
Algoritmo Dynamic Time Warping - Adaptado de (Souza et al., 2009).
Sejam:
x = [ ], o vetor de entrada;
y = [ ], o vetor de referęncia;
n, o comprimento do vetor de entrada;
m, o comprimento do vetor de referęncia.
1. Criaçăo de uma matriz de distâncias acumuladas (dtw = [n x m]).
1.1. O primeiro elemento de dtw será a distância absoluta entre x(1) e y(1).
1.2. Para a primeira linha, calcula-se, para cada elemento, a soma da distância absoluta dos itens de mesma posiçăo dos vetores x e y com o elemento da coluna anterior.
1.3. Para a primeira coluna, calcula-se, para cada elemento, a soma da distância absoluta dos itens de mesma posiçăo dos vetores x e y com o elemento da linha anterior.
1.4. Os outros elementos săo calculados através da soma da distância absoluta dos elementos de cada posiçăo com o menor dentre os seus antecessores imediatos (ŕ esquerda, abaixo e ŕ diagonal).
2. Partindo do ponto final, escolhe-se o menor valor dentre os elementos mais próximos ŕ esquerda, abaixo e ŕ diagonal, até o ponto inicial. Depois, é feita a soma dos valores relacionados ao caminho percorrido. No caso de valores iguais, a preferęncia é da diagonal.
3. Calcula-se a distância DTW por meio da divisăo da soma dos elementos do melhor caminho pelo tamanho do vetor de referęncia.
De acordo com Jayadevan et al. (2009), o melhor caminho entre duas sequęncias a ser calculado deve seguir as seguintes condiçőes:
1) Condiçăo de fronteira: O caminho deve começar pela célula (1,1) e terminar em (n, m), ou seja, o início se dá no canto superior esquerdo e o fim, no canto inferior direito.
2) Condiçăo de continuidade: O caminho deve avançar entre células adjacentes. Ambos os índices (Xk e Yk).
3) Monotonicidade: O caminho nunca poderá voltar sobre si mesmo. Para isso, os índices de (Xk e Yk) devem permanecer iguais ou aumentar, mas nunca diminuir.
Jain et al. (2002) propőem uma forma de comparaçăo de vetores através de um método que permite a re-conexăo de vetores com traços interrompidos. Contudo, este método inclui uma penalidade desencorajar a comparaçăo de dois vetores com grande diferença no número de traços detectados. Uma vez detectado o alinhamento entre duas assinaturas, a diferença entre o número de traços entre elas é incorporado ŕ medida de desigualdade. A fórmula proposta da desigualdade geral entre a assinatura de entrada (I) e a assinatura de referęncia (R) é dada por:
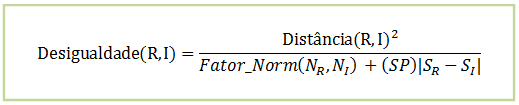
Onde:
Distância (R, I) é a medida da distância obtida depois do alinhamento entre os vetores R e I;
SP é a penalidade de comparaçăo entre assinaturas com número de traços diferentes;
|Sr - Si | é a diferença entre o número de traços entre o modelo e o vetor de entrada e;
Fator_Norm (Nr, Ni) é a maior distância possível entre dois vetores de tamanho Nr e Ni multiplicados por uma constante.
Verificaçăo
O processo de verificaçăo consiste na comparaçăo de todas as assinaturas com o conjunto de referęncia. Uma vez que a medida de similaridade (ou desigualdade) é obtida, deve-se decidir se uma assinatura pode ser aceita como autęntica, ou se é rejeitada como uma fraude. Para isto, é realizada uma comparaçăo com um dado valor limitante (threshold). No caso de a medida de similaridade ser maior que o limiar, a assinatura é aceita, caso contrário, é rejeitada. Se a medida utilizada for a desigualdade, a assinatura só é reconhecida como autęntica se o valor comparado ao limite de aceitaçăo for menor que este.
Segundo Jain et al. (2002), é possível escolher um valor limitante comum a todos os usuários ou criar um valor específico para cada pessoa:
Um threshold comum tem a vantagem de utilizar todos os registros de todos os usuários para encontrar um valor limitante ótimo. As desigualdades entre todas as assinaturas dos escritores existentes no sistema săo computadas e, baseado em um critério mínimo de erro, um valor limitante é escolhido.
Para adaptar o processo de verificaçăo ŕs propriedades de cada usuário, a alternativa seria utilizar um valor limitante específico para cada pessoa. Ŕ princípio, um threshold específico deveria ser obtido somente do conjunto de dados fornecidos por um determinado escritor. Porém, para garantir a confiança do sistema, normalmente săo necessários mais dados do que os disponíveis. Para contornar este problema, geralmente é feita a modificaçăo de um threshold comum através da adiçăo de componentes específicos ŕ cada usuário (Jain et al., 2002).