HMMs
O modelo oculto de Markov (Hidden Markov Model) é um modelo estatístico baseado em processos de Markov, que possui probabilidades condicionais, e geração de saídas a cada estado. Um modelo HMM é dito oculto quando os estados não são visíveis, mas sim as saídas emitidas por eles.
No caso de reconhecimento de fala, o modelo pode ser visto como um espaço de estados finito no qual cada estado representa uma palavra, um fonema ou parte de um fonema, havendo troca de estado a cada unidade de tempo. As saídas geradas por cada estado são vetores acústicos que carregam consigo uma função de densidade de probabilidade associada, e são caracterizadas por um modelo de misturas de gaussianas (GMM). Os parâmetros do modelo são então a matriz A de probabilidades de transição de estados (que carrega os coeficientes a12, a22, a23,...), a matriz π de probabilidades de um modelo ser iniciado a partir de determinado estado e a matriz B de probabilidade de emissão de vetores acústicos b e parâmetros µ e ∑ das gaussianas desses vetores emitidos.
O modelo de HMM a seguir apresenta 3
estados além de um estão inicial e um estado final, existentes para a
facilitação do modelo.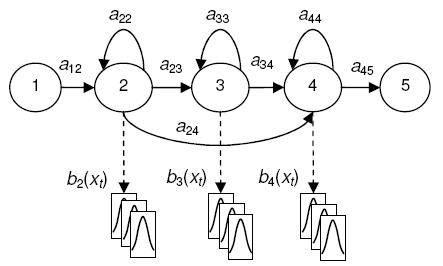
![]()
![]()
Adaptada de [11]
A: matriz de probabilidades de transição de estados
B: matriz de probabilidades de ocorrência de vetores acústicos
b e parâmetros de média µ e variância ∑ de gaussianas
π: matriz de probabilidades de um modelo ser iniciado a partir
de determinado estado. [12]
Já que o modelo não conhece inicialmente qual sequência de estados será descrita, um algoritmo é feito considerando-se todas as sequências de estados possíveis e calculando a probabilidade de ocorrência de cada uma delas.
A tarefa do modelo é então ajustar os parâmetros de modo que haja a maximização da verossimilhança dos vetores observados. Com isso, o HMM modela continuamente elocuções gerando vetores acústicos e os compara com dados na base feitos na fase de teste para decidir o reconhecimento.
![]()
![]()
