· Principal
· Introduçăo
· Utilizaçăo
· Classificaçăo
· RIP
· Bibliografia
· Perguntas
RIP
O RIP (Routing Information Protocol) foi um dos primeiros protocolos IGP e foi muito popularizado pela implementaçăo da ferramenta routed, muito usada em sistemas UNIX 4BSD. Este protocolo é derivado de um protocolo da Xerox para redes locais. Basicamente, ele trata da implementaçăo direta do algoritmo de vetor distância. A RFC do RIP, saiu em 1988 (RFC 1058).
Por ser baseado no algoritmo de vetor distância, este protocolo envia copias periódicas de sua tabela de roteamento para seus vizinhos diretamente conectados (utiliza o endereço broadcast de cada rede diretamente conectada). Roteadores que estăo utilizando esse protocolo enviam atualizaçőes periódicas mesmo que năo ocorram alteraçőes na rede.
As mensagens periódicas do RIP săo cópias da tabela de roteamento completa de cada roteador. Quando um roteador recebe a tabela de roteamento completa de seu vizinho, ele verifica cada rota, acrescentando as que ele ainda năo conhecia em sua tabela e comparando as já existentes para escolher aquela com o menor número de saltos para colocar em sua tabela ou atualizar entradas já existentes.
Porém existem situaçőes onde ocorre a transmissăo de informaçőes erradas. A seguir vamos mostrar um caso destes, assim como as ferramentas utilizadas pelo RIP para tentar evitar tais inconsistęncias.
Temos o ambiente abaixo.
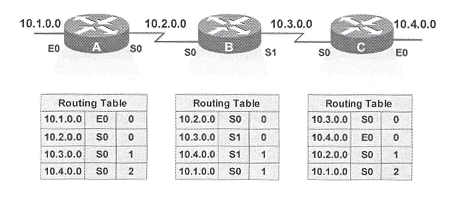
Ocorre, porém, uma falha e a rede 10.4.0.0 năo está mais disponível. O roteador C, diretamente conectado a esta rede, detecta a falha e para de enviar pacotes para ela. Porém, os roteadores A e B ainda năo receberam o aviso de que a rede 10.4.0.0 caiu. O roteador A, ainda acredita que pode acessar esta rede através do roteador B (sua tabela de roteamento continua a marcar uma distancia de 2 saltos até ela).
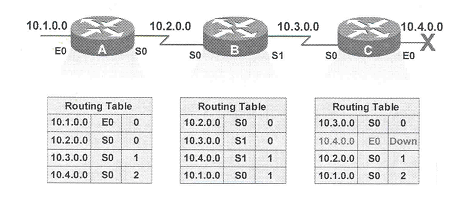
Quando o roteador B envia a copia periódica de sua tabela de roteamento para o roteador C, este acredita que agora ele consegue novamente alcançar a rede 10.4.0.0, porém, agora, a partir do roteador B. O roteador C atualiza sua tabela de roteamento com a rota de destino a rede 10.4.0.0 via roteador B com número de saltos igual a 2.
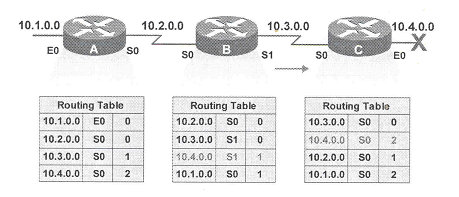
Agora, o roteador B recebe a atualizaçăo vinda do roteador C. Como o roteador B já possui em sua tabela uma entrada para a rede 10.4.0.0 aprendida a partir da sua interface serial 1, ao receber esta atualizaçăo (também vinda via serial 1), ela irá atualizar a distância para esta entrada. Logo, o roteador B irá atualizar sua tabela com o novo custo, agora de 3, para alcançar esta rede. O mesmo irá ocorrer com o roteador A, ao receber a tabela do roteador B. O roteador A também detecta uma alteraçăo na distância da rede 10.4.0.0 e atualiza sua tabela, colocando como 4 a distância até esta rede.
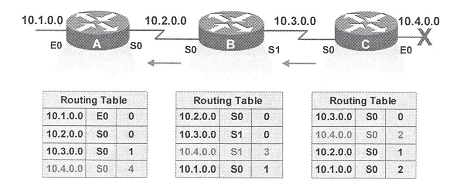
Neste momento, temos todas as 3 tabelas de roteamento incorretas. Todas prometem alcançar a rede 10.4.0.0 por caminhos inexistentes. Estas atualizaçőes erradas văo se repetir e a contagem de saltos vai crescer cada vez mais. Este problema é conhecido como contagem para o infinito (count to infinity). Pacotes destinados a rede 10.4.0.0 nunca alcançaram o destino mas văo ficar trafegando continuamente na rede (loop de roteamento) desperdiçando banda.
A seguir serăo apresentadas algumas soluçőes para minimizar os problemas apresentados pelo algoritmo de vetor distância.
Este problema apresentado como contagem para o infinito acontece, como vimos, sempre que as tabelas de roteamento continuam a aumentar a métrica para um destino que năo pode ser alcançado, ao invés de marcar este destino como inalcançável. Para que isto năo ocorra, o protocolo define um número máximo de saltos, este número máximo, no caso do RIP, é 16. Agora, o protocolo de roteamento irá permitir que, no caso de ocorręncia de loop de atualizaçăo, este irá ocorrer até a métrica alcançar este valor máximo permitido. Quando a métrica exceder o valor máximo permitido a rede é considerada inalcançável, parando a proliferaçăo de atualizaçőes de roteamento que aumentem esta métrica. Isso de um lado limita o tamanho da rede, mas evita que um pacote permaneça na rede infinitamente.
Temos ainda soluçőes para eliminar estes loops de roteamento. Loops de roteamento ocorrem quando dois ou mais roteadores tem informaçőes erradas de roteamento indicando um caminho válido para uma rede inalcançável passando pelo outro.
Exemplo:
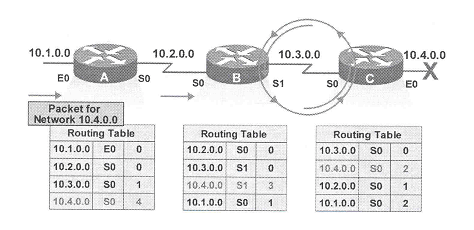
Neste exemplo, um pacote destinado a rede 10.4.0.0 chega ao roteador A. Este olha na sua tabela de roteamento e manda o pacote pela sua interface serial 0. Ao chegar no roteador B, este manda o pacote pela sua interface serial 1, como indicado na sua tabela de roteamento. O roteador C recebe o pacote e checa sua tabela de roteamento, a qual especifica que o pacote deve ser enviado pela interface serial 0. O pacote entăo, acaba voltando ao roteador B que novamente o envia para o roteador C. O pacote ficará entăo trafegando de B para C.
Existem algumas técnicas disponíveis para eliminar loop de roteamento como: estreitamento de horizontes (split horizon), envenenamento de rotas (route poisoning), envenenamento reverso (poison reverse), tempo de espera ( holddown timers) e atualizaçőes imediatas (triggered updates). A seguir tem-se uma explicaçăo de cada uma destas técnicas.
Estreitamento de horizontes (Split Horizon)
Uma maneira de se eliminar os loops de roteamento a aumentar a velocidade de convergęncia é utilizando a técnica de estreitamento de horizontes. Esta técnica diz que năo é útil mandar informaçőes sobre uma rota de volta na mesma direçăo por onde a informaçăo original chegou. Ou seja, evita que um roteador RIP propague rotas para a mesma interface que ele aprendeu, evitando loop entre estes nós.
Envenenamento de rotas (Route Poisoning)
Esta técnica é uma ligeira modificaçăo daquela utilizada no estreitamento de horizontes. Seu objetivo também é a prevençăo de loops de roteamento causados por atualizaçőes inconsistentes. Com essa técnica, o roteador seta a entrada da tabela que mantém o estado da rede consistente, enquanto os demais roteadores gradativamente convergem corretamente após a ocorręncia de uma mudança na topologia. Utilizado juntamente com o tempo de espera, uma outra técnica que será mostrada mais a frente, o envenenamento de rotas é uma soluçăo para loops longos. Ou seja, no caso estudado, quando o enlace 10.4.0.0 fica indisponível, o roteador C (diretamente conectado a ele) envenena este enlace. Em sua tabela, ele coloca esta rede como inalcançável ou de métrica infinita (número de saltos igual a 16). Tendo envenenado a rota para este enlace, o roteador C năo fica sujeito a atualizaçőes incorretas a respeito deste enlace, vindas de roteadores vizinhos que acreditam ter rotas alternativas para ele.
Envenenamento Reverso (Poison Reverse)
Estreitamento de horizontes com envenenamento reverso faz com que a rede consiga convergir em menos tempo. Quando o roteador B recebe uma atualizaçăo mostrando que a métrica para se atingir a rede 10.4.0.0 foi alterada para infinito, ele manda uma atualizaçăo, chamada de envenenamento reverso, de volta para o roteador C avisando que a rede está inalcançável. E ainda coloca este enlace como possivelmente inalcançável em sua tabela de roteamento. Essa é uma situaçăo específica que se sobrepőe ao estreitamento de horizontes. Isso ocorre para ter certeza que o roteador C năo ficará sujeito a atualizaçőes erradas a respeito desta rede.
Tempo de Espera (Holddown Timers)
O tempo de espera é utilizado para evitar que atualizaçőes inapropriadas ensinem caminhos inexistentes para enlaces que năo estăo disponíveis. Com esta técnica, os roteadores esperam por mudanças que devem afetar rotas, por algum período de tempo. Esse período, por padrăo do RIP, é de 3 vezes o tempo da atualizaçăo periódica (por padrăo, o RIP manda atualizaçőes temporárias a cada 30s).
Situaçőes onde este tempo é utilizado:
- Quando um roteador recebe uma atualizaçăo de um vizinho indicando que uma rede que era acessível agora năo está mais. O roteador entăo, marca a rota como possivelmente inalcançável (possible down) e começa a marcar seu tempo de espera.
- Se a atualizaçăo de algum vizinho chegar com métrica melhor do que aquela que está na tabela de roteamento do enlace possivelmente inalcançável, o roteador marca o enlace como alcançável e retira o tempo de espera.
- Se em qualquer momento, antes do tempo de espera estourar, o roteador receber uma atualizaçăo de um vizinho diferente, com uma métrica mais fraca ou igual aquela da rede possivelmente inalcançável, esta será descartada. Ignorando estas atualizaçőes de métricas piores enquanto estiver em tempo de espera, o roteador que percebeu a mudança dá mais tempo aos demais roteadores para que estes sejam avisados de uma mudança na rede.
- Durante este tempo de espera, as rotas aparecem como possivelmente inalcançáveis nas tabelas de roteamento. Mesmo com a rota estando no estado de possivelmente inalcançáveis, os roteadores continuam tentando encaminhar os pacotes para essa rede (talvez esta rede só esteja tendo um problema de conexăo intermediária, oscilaçăo...)
Atualizaçőes Imediatas (Triggered Updates)
Nos exemplos anteriores, os loops de roteamento foram causados graças as informaçőes erradas obtidas como resultado de atualizaçőes inconsistentes, convergęncia lenta e temporizaçăo. O fato dos roteadores esperarem por suas atualizaçőes periódicas para notificar aos demais uma alteraçăo na rede, faz com que a rede tenha um tempo de convergęncia mais lento.
Normalmente, as atualizaçőes nas tabelas de roteamento săo passadas aos demais em um intervalo de tempo constante. Essa ferramenta propőe que sejam mandadas atualizaçőes imediatas assim que um roteador perceber uma alteraçăo na rede. O roteador que percebe a mudança passa entăo imediatamente aos seus vizinhos esta atualizaçăo, estes ao receberem a atualizaçăo, também a passarăo imediatamente para seus demais vizinhos e assim a atualizaçăo chega mais rapidamente aos roteadores envolvidos.
Essa idéia de atualizaçăo imediata seria suficiente se pudesse garantir que cada uma destas atualizaçőes chegasse imediatamente aos roteadores apropriados. Porém, podem ocorrer dois problemas:
- Os pacotes de atualizaçăo podem ser descartados ou corrompidos ao longo de sua trajetória.
- As atualizaçőes imediatas năo ocorrem instantaneamente. É possível que um roteador que ainda năo recebeu esta atualizaçăo imediata envie sua atualizaçăo periódica, fazendo com que seu vizinho que acabara de atualizar sua tabela devido a atualizaçăo imediata que ele recebeu, coloque a rota novamente em sua tabela.
Agora, juntando as atualizaçőes imediatas com o tempo de espera o problema é solucionado. Por que com o tempo de espera, mesmo que o alguém envie uma atualizaçăo temporária antes de receber a atualizaçăo imediata, os demais roteadores que já haviam recebido as atualizaçőes imediatas e haviam posto tal rota como possivelmente inalcançável, ao receberem um caminho alternativo com métrica pior ou igual a que eles conheciam, năo atualizem suas tabelas enquanto o tempo năo houver estourado. Isso faz com que a atualizaçăo imediata tenha mais tempo para percorrer todos os roteadores envolvidos antes destes tentarem divulgar um novo caminho até a rede que foi modificada.
Características
A seguir temos algumas das principais características do RIP:
- É um protocolo relativamente antigo mais ainda é bastante utilizado em redes pequenas.
- Por se tratar de um protocolo antigo e simples, quase todos os roteadores podem utilizar o RIP.
- É de fácil configuraçăo (pouca complexidade).
- É um protocolo baseado no algoritmo de vetor distancia.
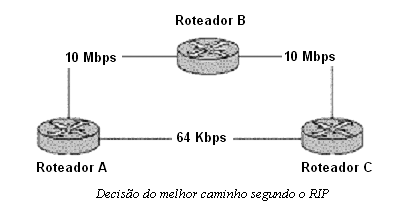
- Contagem de saltos é utilizada como a única métrica para a seleçăo de caminhos. Isso faz com que nem sempre o melhor caminho seja armazenado na tabela de roteamento. Um exemplo dessa situaçăo é mostrado abaixo, onde de A para C existem dois caminhos. Um deles é pelo roteador B, tendo custo em 2 saltos e o outro seria diretamente com custo 1. Mesmo que os links pelo roteador B sejam muito superiores em capacidade, ou ainda, mesmo que o link de 64 Kbps esteja totalmente utilizado, o melhor caminho escolhido pelo RIP sempre será pelo link de 64 Kbps já que a única métrica é o número de saltos.
- O número máximo de saltos permitidos é 15. Isso limita o uso deste
protocolo a redes năo muito grandes, mas como ele é um IGP, este número
parece razoável. O RIP é projetado para intercambiar informaçőes de
roteamento em uma rede de tamanho pequeno para médio.
- Atualizaçőes periódicas de roteamento a cada 30 segundos por padrăo.
Mesmo que năo exista nenhuma alteraçăo nas rotas da rede, os roteadores
baseados em RIP, continuarăo a trocar mensagens de atualizaçăo nestes
intervalos regulares. Dentre outros, este é mais um dos motivos pelos
quais o RIP năo é indicado para redes maiores, pois nestas situaçőes
o volume de tráfego gerado pelo RIP, poderia consumir boa parte da banda
disponível. Além disso, cada mensagem do protocolo RIP comporta, no
máximo, informaçőes sobre 25 rotas diferentes, o que para grandes redes,
faria com que fosse necessária a troca de várias mensagens, entre dois
roteadores, para atualizar suas respectivas tabelas, com um grande número
de rotas.
- RIP é capaz de fazer balanceamento de carga em até 6 caminhos porém
estes devem ser de custo iguais. Basta definir o número máximo de caminhos
paralelos permitidos na tabela de roteamento. Com o RIP, estes caminhos
devem ser de custo iguais. Caso năo seja do interesse trabalhar com
balanceamento de cargas, basta escolher esse número máximo de caminhos
paralelos como 1.
- A primeira versăo do RIP, o RIPv1 criada em 1988, que ainda é utilizada
atualmente, é implementada como sendo um protocolo de roteamento classful,
isso significa que ele năo manda a máscara de rede das rotas que ele
divulga em suas atualizaçőes. Devido a essa característica, năo podemos
trabalhar com redes de tamanho de mascara variado. (Variable Lenght
Subnet Mask- VLSM). O RIPv1 foi desenvolvido para trabalhar com redes
baseadas nas classes padrăo A, B e C, ou seja, pelo número IP da rota,
deduzia-as a respectiva classe. Com o uso da Internet e o uso de um
número variável de bits para a máscara de sub-rede (número diferente
do número de bits padrăo para cada classe), esta fato tornou-se um problema
sério do protocolo RIP v1. O protocolo RIP v1, utiliza a seguinte lógica,
para "descobrir" qual a máscara de sub-rede associada com determinada
rota:
1. Se a identificaçăo de rede coincide com uma das classes padrăo A,
B ou C, é assumida a máscara de sub-rede padrăo da respectiva classe.
2. Se a identificaçăo de rede năo coincide com uma das classes padrăo,
duas situaçőes podem acontecer.
2.1 Se a identificaçăo de rede coincide com a identificaçăo de rede
da interface na qual o anúncio foi recebido, a máscara de sub-rede da
interface na qual o anúncio foi recebido, será assumida.
2.2 Se a identificaçăo de rede năo coincide com a identificaçăo de rede
da interface na qual o anúncio foi recebido, o destino será considerado
um host (e năo uma rede) e a máscara de sub-rede 255.255.255.255, será
assumida.
- As atualizaçőes periódicas do RIPv1 utilizam o endereço de broadcast.
Com isto, todos os hosts da rede receberăo os pacotes RIP e năo somente
os hosts habilitados ao RIP.
- O RIPv2, a versăo 2 do RIP que surgiu em 1993, já é um protocolo de
roteamento classless , ou seja, envia a mascara das redes divulgadas
em suas atualizaçőes. Já permitindo trabalhar com redes de tamanho de
máscara variado.
- Outra melhora do RIPv2, é que este é mais seguro pois utiliza autenticaçăo,
o que visa proteger a rede contra utilizaçăo de roteadores năo autorizados.
Com o RIPv2 é possível implementar um mecanismo de autenticaçăo, de
tal maneira que os roteadores somente aceitem os anúncios de roteadores
autenticados, isto é, identificados na rede. A autenticaçăo pode ser
configurada através da definiçăo de uma senha ou de mecanismos mais
sofisticados como o MD5 (Message Digest 5). Por exemplo, com a autenticaçăo
por senha, quando um roteador envia um anúncio, ele envia juntamente
a senha de autenticaçăo. Outros roteadores da rede, que recebem o anúncio,
verificam se a senha está correta e somente depois da verificaçăo, alimentam
suas tabelas de roteamento com as informaçőes recebidas.
- Os anúncios de atualizaçăo do protocolo RIPv2 săo baseados em tráfego
multicast e năo mais broadcast como no caso do protocolo RIPv1. O protocolo
RIPv2 utiliza o endereço de multicast 224.0.0.9. Com isso os roteadores
habilitados ao RIPv2 atuam como um grupo multicast, registrado para
"escutar" os anúncios do protocolo. Outros hosts da rede, năo habilitados
ao RIPv2, năo serăo "importunados" pelos pacotes deste protocolo. Por
questőes de compatibilidade (em casos onde parte da rede ainda usa o
RIP v1), é possível utilizar broadcast com roteadores baseados em RIP
v2. Mas esta soluçăo somente deve ser adotada durante um período de
migraçăo, assim que possível, todos os roteadores devem ser migrados
para o RIPv2 e o anúncio via broadcast deve ser desabilitado.
- É importante mencionar que tanto redes baseadas no RIPv1 quanto no
RIPv2 săo redes chamadas planas (flat). Ou seja, năo é possível formar
uma hierarquia de roteamento, baseada no protocolo RIP. Mais um motivo
para o RIP năo ser utilizado em grandes redes. A tendęncia natural do
RIP, é que todos os roteadores sejam alimentados com todas as rotas
possíveis (isto é um espaço plano, sem hierarquia de roteadores). Imagine
como seria utilizar o RIP em uma rede como a Internet, com milhőes e
milhőes de rotas possíveis, com links caindo e voltando frequentemente?
Impossível. Por isso que o uso do RIP (v1 ou v2) somente é indicado
para pequenas redes.
- O RIPv1 é descrito na RFC 1058 e a versăo 2 (RIPv2) nas RFCs 1721
e 1722.