
Uma Breve História das Chamadas Distribuídas
Apesar do artigo de 1984 entitulado "Implementing Remote Procedure Calls", de autoria de Andrew Birrell e Bruce Nelson, ter sido revolucionário para a área, a ideia de RPC é bastante antiga. Discutida publicamente na literatura desde pelo menos 1976 e presente na própria tese de doutorado de Bruce Nelson, seu número de implementações era altamente menor que seu número de teses. Sistemas desta natureza não eram exatamente comuns no início dos anos 1980, e foi apenas com a publicação de tal artigo que os dois pesquisadores do Xerox Palo Alto Research Center (PARC) deram início a sua difusão. Anteriormente, a complexidade de tais arquiteturas explicava a dificuldade em engenheirar sistemas de chamadas remotas. Entre os desafios encontrados, alguns se destacavam:
- a especificação da semântica no caso de uma falha da máquina ou da comunicação;
- a semântica para argumentos com endereços (ex.: ponteiros) num contexto de diferentes espaços de endereçamento;
- integrar chamadas remotas a sistemas existentes e futuros;
- a maneira que o cliente determina o endereço e a identidade do servidor;
- necessidade de um protocolo para a transferência e controle de dados entre as duas partes;
- e como prover, caso desejado, integridade dos dados e segurança em um ambiente de comunicação aberta.
No artigo em questão, apesar de não entrarem em detalhes, os autores descrevem uma abordagem para cada um destes desafios, abrindo espaço para uma grande quantidade de avanços que viriam posteriormente. Por exemplo, para o problema de falhas, os autores propuseram uma sondagem, realizada por um "probe packet", através do qual o cliente sonda periodicamente o servidor para saber se sua chamada remota está sendo processada como previsto. Em geral, o ambiente de chamadas remotas estava começando a ser consolidado, ao mesmo tempo em que um outro paradigma surgia no horizonte.
O Paradigma de Orientação a Objetos
Por muitos anos, o paradigma procedural reinou nas linguagens de programação. Seu funcionamento, como descrito por Bjarne Stroustrup, criador da linguagem C++, em seu artigo "What is "Object-Oriented Programming"? (1991 revised version)" (traduzido abaixo), pode ser resumido através da seguinte máxima:
Para Stroustrup, olhando por um ponto de vista organizacional de programa, as funções são usadas para criar ordem em um labirinto de algoritmos. Seria necessário, portanto, esconder dados dependendo do nível de abstração que se deseje utilizar em diferentes momentos na formulação de um programa. Deveríamos, portanto, agrupar as diferentes componentes que participam da resolução de nossos problemas em módulos, com os quais interagiríamos através de métodos cujas implementações, dado um grau de abstração alto o suficiente, não interessariam desde que fossem minimamente eficientes. Assim, deveríamos trocar nossa máxima para:
Apesar desta não ser a única premissa desse novo paradigma, a descrição acima caracteriza bem a essência de abstração dessa nova maneira de pensar e nos dá bagagem suficiente para entendermos as diferenças principais entre o RPC, proposto nos anos 1980, e o RMI, idealizado nos anos 1990 já sob esta nova ótica de estruturação de dados.
Diferenças Entre os Modelos
Tendo falado sobre os paradigmas por trás de cada uma das duas opções de chamadas distribuídas, fica fácil ver pelo menos uma diferença essencial entre os dois. Indo direto ao ponto, o RPC funciona sob o paradigma funcional, enquanto o RMI opera sob o paradigma de orientação a objetos. O RPC trabalha com funções, enquanto o RMI vive de métodos pertencentes a objetos.
Além desta diferença básica, há a distinção de linguagens. Apesar de ser implementada em mais de uma linguagem, a técnica de Remote Procedure Call é baseada em C, herdando sua estruturação básica. RMI, por outro lado, foi desenvolvido exclusivamente para Java e usa sua respectiva máquina virtual (Java Virtual Machine - JVM). As semânticas que os protocolos implementam também têm suas peculiaridades: enquanto o RPC incorpora semânticas como "no-máximo-uma vez" ou "pelo-menos-uma-vez", o RMI apenas implementa "no-máximo-uma vez".
Apesar da implementação das duas técnicas também ser muito diferente, a última distinção que vale a pena ser notada é o fato de que RMI, por ser inspirado por este paradigma de orientação a objetos, ajuda a deixar o código dos programas mais limpo. Se, por exemplo, um objeto muda de classe, o programa continua funcionando normalmente desde que os mesmos métodos da classe anterior estejam implementados. Um exemplo é uma troca entre uma pilha e uma fila, que muitas vezes possuem métodos com o mesmo nome mas implementados de forma diferente.
Semelhanças Entre os Modelos
Apesar de haver um considerável número de diferenças entre os dois modelos de computação distribuída, muitos dos conceitos básicos se repetem em ambos os paradigmas. O diagrama arquitetural de alto nível, por exemplo, é comum tanto ao RPC quanto ao RMI. Dessa forma, mesmo havendo diferenças acentuadas na implementação de cada um dos dois sistemas distribuídos, sua finalidade comum acaba levando a um diagrama unificado, que traduz os objetivos de ambos os modelos:
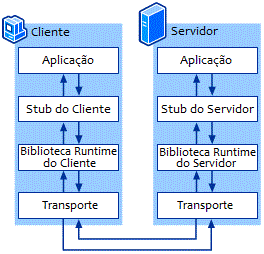
Pela figura, podemos apontar também como semelhança o fato de ambos trabalharem com uma interface. As partes inferiores do diagrama são invisíveis ao programador, que só precisa se preocupar com uma chamada de função ou a invocação de um método. A fim de contribuir ainda mais para a transparência, ambos os modelos empregam sintaxes semelhantes entre chamadas locais e chamadas remotas. Não é necessário utilizar construções verborrágicas e redundantes ao requisitar um recurso remoto que, no fim, está a apenas uma chamada de distância.
No fim, chegamos à conclusão de que RMI e RPC são duas formas diferentes de alcançar o mesmo objetivo.
Apesar de RPC ser mais antiquado e de que o futuro provavelmente seguirá a onda RMI, o uso de cada uma das técnicas depende de fatores como o paradigma sob o qual
o programa é planejado e a relevância de se manter o código um pouco mais limpo. Utilizar um dos modelos é, portanto, uma decisão de projeto, que precisará optar
por uma dessas duas ferramentas que tanto impulsionaram a computação distribuída nas últimas décadas.