Aluno: Rafael Teruszkin
Professor: Otto
Redes de Computadores
Data: 01/06/2002
Balanceamento de Carga
em Servidores Web
O crescimento constante da Internet vem causando diversos
problemas de desempenho, incluindo baixos tempos de resposta, congestionamento
da rede e interrupção de serviços (DOS). Existem diversas abordagens de como
esses problemas podem ser contornados.
![]() Espelhamento do Site
Espelhamento do Site
![]() Servidores Proxy
Servidores Proxy
![]() Balanceamento de Carga
Balanceamento de Carga
Uma abordagem ainda muito usada consiste no espelhamento
do site em diversos locais que podem ser acessados
manualmente pelos usuários através de uma listagem com as URLs
correpondentes. Esse tipo de solução trás diversas
desvantagens como a não transparência ao usuário e ausência de controle na
distribuição de requisições.
Outra abordagem consiste em manter cópias (caches) de objetos Web acessados
perto dos usuários. Isso pode ser controlado por servidores que colocam objetos
Web populares em outros servidores cooperativos ou
ainda disparados por requisições individuais de usuários que passam por um
servidor Proxy. Uma outra técnica consiste em pré-carregar os objetos
freqüentemente acessados de forma a mascarar a latência da rede.
Uma abordagem complementar é fazer o servidor Web mais poderoso através do uso de uma arquitetura em
cluster na qual múltiplas máquinas funcionam como um único servidor.
Um cluster é definido como um grupo de servidores rodando
a mesma aplicação Web simultaneamente, aparecendo
para o mundo como se fosse um único servidor, ou ainda:
“Um sistema paralelo ou distribuído que consiste na
coleção de computadores interconectados que são utilizados como um só, unificando
seus recursos computacionais”
(G. Pfister, um dos arquitetos da tecnologia de clusters)
Esse trabalho trás uma visão geral sobre diversas
implementações de distribuição de carga em clusters de servidores com
aplicações Web. Para balancear a carga nos
servidores, o sistema distribui as requisições para diferentes nós que componham
o cluster de servidores, com um objetivo
de otimizar o desempenho do sistema. Os resultados são:
![]() Alta disponibilidade
Alta disponibilidade
![]() Escalabilidade
Escalabilidade
![]() Administração facilitada da
aplicação
Administração facilitada da
aplicação
Alta disponibilidade pode ser definida como redundância. Se
um servidor falhar ou não puder atender uma requisição, então outro servidor
assumirá, da forma mais transparente o possível, o processamento da requisição.
Isso tende a eliminar os pontos de falha de uma aplicação.
Escalabilidade é a habilidade que uma aplicação tenha de
suportar um crescente número de usuários. Se uma aplicação leva 10 ms para
responder uma requisição, quanto tempo ela levará para responder 10.000
requisições concorrentes? Escalabilidade infinita permitiria que a aplicação
respondesse essa carga em 10 ms; no mundo real a resposta seria num espaço de
tempo indeterminado maior que 10 ms. Escalabilidade é uma medida de vários
fatores, incluindo o número de usuários simultâneos que um cluster pode
suportar e o tempo que se leva para responder uma requisição.
A administração facilitada do sistema é facilitada, no
sentido de que o cluster aparece como um único sistema para os usuários,
aplicações e para o resto da rede, facilitando o acesso e administração do
sistema e dos recursos de rede.
Com respeito às entidades que podem realizar o
balanceamento de carga, podemos subdividi-las em:
![]() Baseada no Cliente
Baseada no Cliente
![]() Baseada no DNS
Baseada no DNS
![]() Baseada num Despachante
Baseada num Despachante
![]() Baseada no Servidor
Baseada no Servidor
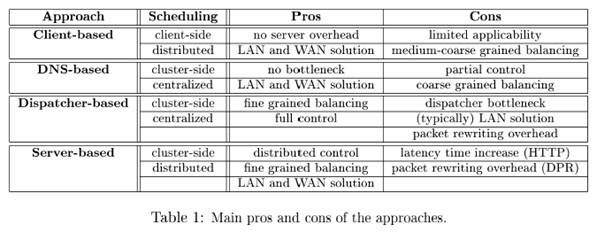
Existem duas abordagens de como colocar o mecanismo de
seleção de servidores no lado do cliente
satisfazendo o requisito de transparência: através dos próprios clientes (browsers) ou por meio de servidores Proxy (também visto com
um cliente). Em ambos os casos, é necessário um prévio
conhecimento sobre a estrutura que está sendo balanceada (Ex. Netscape).
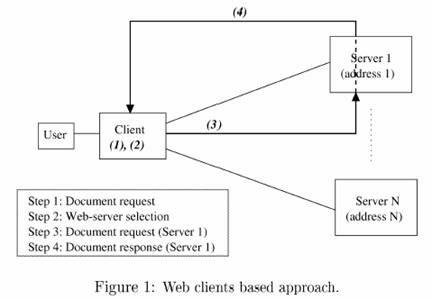
As arquiteturas distribuídas de servidores Web que utilizam mecanismos de roteamento no lado do
cluster não sofrem as limitações das soluções baseadas no lado do cliente.
Tipicamente a transparência da arquitetura é obtida através de uma única interface virtual direcionada ao
mundo externo, pelo menos ao nível da URL.
Numa primeira solução desenvolvida no lado do cluster, a
responsabilidade de distribuir as requisições entre os servidores é atribuída
ao DNS do cluster, ou melhor, ao
servidor de DNS autoritário pelo domínio dos nós do cluster. Através de um
processo de tradução entre os nomes simbólicos (URL) e endereços IP, o DNS do
cluster pode selecionar qualquer nó que compõe o cluster.
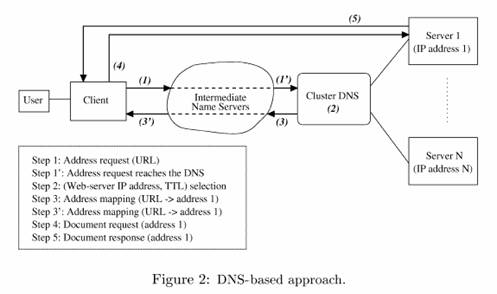
Deve-se observar a limitação de controle que essa solução
dispõe devido aos muitos servidores de nome intermediários entre o cliente e o
DNS do cluster, sem contar o próprio cache do browser cliente. Há também um problema de disponibilidade
quando um dos nós do cluster falha e o DNS continua apontando
requisições sem perceber a falha.
O algoritmo normalmente utilizado nessa seleção é o Round Robin.
Nas demais abordagens que serão discutidas também são
utilizados outros algoritmos para seleção de nós do cluster que,
dependendo da situação, podem ter melhor ou pior performance.
![]() Seleção Randômica
Seleção Randômica
![]() Seleção com Round Robin (RR)
Seleção com Round Robin (RR)
![]() Seleção por menor Carga – Least Loaded (LL)
Seleção por menor Carga – Least Loaded (LL)
![]() Seleção por menos conexões – Least Connections (LC)
Seleção por menos conexões – Least Connections (LC)
Uma abordagem alternativa à arquitetura baseada em DNS
visa ter total controle sobre as requisições de clientes e mascarar o
roteamento entre múltiplos servidores. Para esse propósito, a virtualização de endereço realizada na solução
baseada em DNS é estendida do nível da URL para o nível do IP. Nessa abordagem
um único endereço IP virtual é fornecido ao cluster Web.
Esse é o endereço do chamado "despachante"
que atua com escalonador central do cluster.
Para distribuir a carga, o despachante reconhece cada nó
do cluster através de um endereço privado que pode ser num nível de protocolo
diferente, dependendo da arquitetura proposta. As duas principais maneiras
usadas de se rotear são através de um mecanismo de reescrita de pacotes e por redirecionamento HTTP.
A reescrita de pacotes pode ser feita de forma simples ou
dupla pelo despachante do cluster. Na forma simples o despachante reescreve os
pacotes de entrada e o servidor reescreve os pacotes de saída. Na forma dupla,
ambos pacotes são reescritos pelo despachante num mecanismo baseado em NAT.
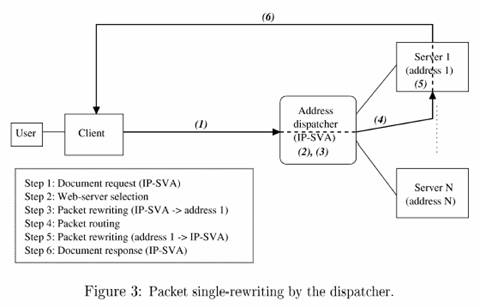
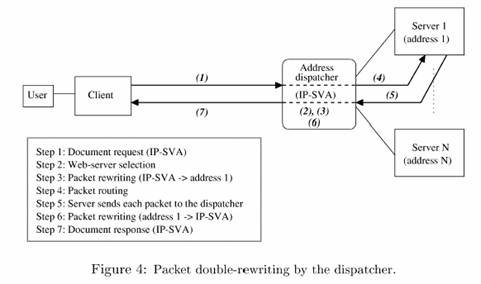
No redirecionamento por HTTP, o
despachante do cluster recebe os pacotes entrantes e distribui pelos nós
servidores através de um mecanismo provido pelo protocolo HTTP. Através desse
protocolo o despachante redireciona a requisição com código de status
apropriado e indicando no cabeçalho o endereço do servidor para o qual o
cliente deve enviar as requisições.
As técnicas de balanceamento de carga baseadas nos servidores do cluster utilizam um mecanismo de
direcionamento de pacotes em dois níveis. As requisições de clientes são
inicialmente direcionadas do DNS do cluster para os servidores. Cada servidor
então pode direcionar a requisição para outro nó qualquer do cluster.
Diferente das soluções baseadas em DNS e num despachante
central, essa abordagem baseada em escalonamento
distribuído permite que os servidores participem do balanceamento da carga
através de um mecanismo de requisições e (re)direcionamentos.
Duas classes de soluções serão consideradas aqui. As
baseadas num mecanismo de reescrita de
pacotes e aquelas que tomam vantagem da facilidade de redirecionamento do protocolo HTTP.
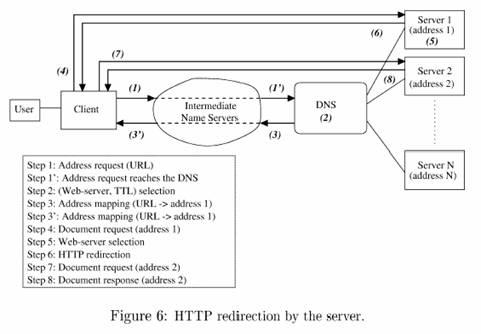
Cada servidor decide sobre o redirecionamento
baseado em critérios que visam minimizar o tempo de resposta a
requisição do cliente. A estimativa desse tempo é feita tomando as capacidades
de processamento de cada servidor, banda e atrasos.
Todos os mecanismos de redirecionamento
propostos implicam num overhead às comunicações internas ao cluster, pois cada
nó precisa transmitir periodicamente seu status para os outros nós e para o DNS
do cluster. Esse custo, porém, tem um efeito insignificante no tráfego de rede
gerado pelas requisições de clientes.
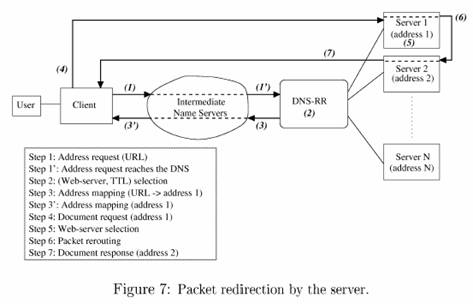
No redirecionamento de pacotes
pelo servidor é usado o mecanismo de Round Robin no
DNS para realizar o primeiro escalonamento das requisições entre os nós do
cluster. O servidor que recebe uma requisição está habilitado a re-roteá-la para
outros nós através do mecanismo de reescrita de pacotes que, diferente do redirecionamento por HTTP, é transparente ao cliente.
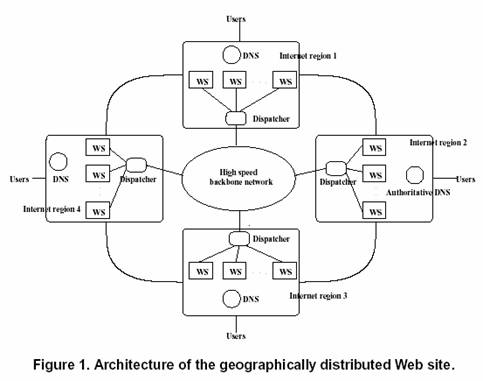
![]() Solução
Mista: Balanceamento Geográfico para
Sistemas Web Distribuídos e Escaláveis
Solução
Mista: Balanceamento Geográfico para
Sistemas Web Distribuídos e Escaláveis
![]() Estudo
de Caso: Microsoft Network
Load Balance (NLB) e Microsoft Cluster Services (MSCS)
Estudo
de Caso: Microsoft Network
Load Balance (NLB) e Microsoft Cluster Services (MSCS)
![]() Cluster Services
(MSCS)
Cluster Services
(MSCS)
Projetado para suportar falhas em servidores back-end como banco de dados, sistemas de mensagens,
repositório de arquivos e impressoras.
![]() Network Load Balancing
(NLB)
Network Load Balancing
(NLB)
Realiza a distribuição de carga de requisições IP por
múltiplos servidores do tipo front-end. Indicado para
servidores internet como web
servers, streaming media servers, e Terminal Services.
|
Cenário |
MSCS |
NLB |
Benefícios |
|
Web Server Farm |
|
X |
|
|
Terminal Servers |
|
X |
|
|
File/Print Servers |
X |
|
|
|
Database/Messaging |
X |
|
|
|
E-Commerce Sites |
X |
X |
|
|
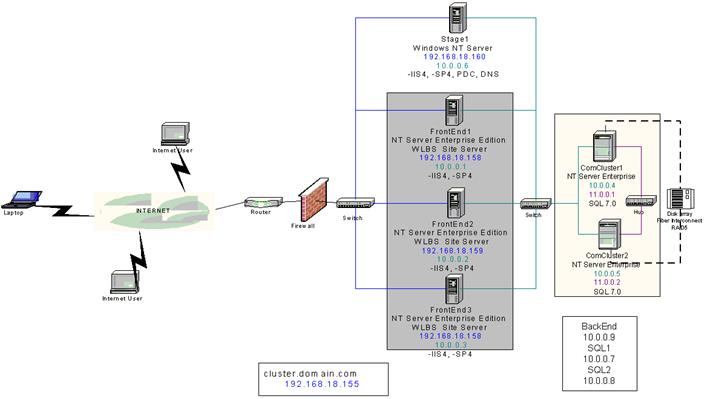
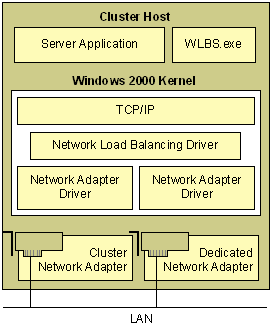
Arquitetura do NLB O NLB funciona como um driver
intemediário entre o protocolo TCP/IP
e os drivers da placa de rede na pilha de
protocolos do W2K. Apesar de haver 2 placas de rede
na figura, apenas uma é necessária para usar o NLB Pacotes indesejados são filtrados (mais rápido) e
não redirecionados |
|
Gerenciando estado
de aplicações com NLB
![]() Necessidade: sessões de carrinhos de compra em sites
de e-commerce e autenticação de dados usando SSL
Necessidade: sessões de carrinhos de compra em sites
de e-commerce e autenticação de dados usando SSL
![]() Afininidade do Cluster
Afininidade do Cluster
![]() No affinity – Requisições podem cair em
qualquer nó
No affinity – Requisições podem cair em
qualquer nó
![]() Client affinity – Requisições caem sempre no mesmo nó
Client affinity – Requisições caem sempre no mesmo nó
![]() Class C affinity – Requisições de uma mesma classe C caem sempre no mesmo nó (multíplos servidores proxy)
Class C affinity – Requisições de uma mesma classe C caem sempre no mesmo nó (multíplos servidores proxy)
Convergência do NLB
![]() Os
nós do cluster trocam, periodicamente, mensagens em broadcast ou multicast para
monitoração do cluster (heartbeat)
Os
nós do cluster trocam, periodicamente, mensagens em broadcast ou multicast para
monitoração do cluster (heartbeat)
![]() A
convergência é alcançada quando todos os nós chegam a um acordo sobre o estado
do cluster
A
convergência é alcançada quando todos os nós chegam a um acordo sobre o estado
do cluster
![]() O
período padrão dessas mensagens é de 1s. Durante a convergência, esse tempo é reduzido
pela metade
O
período padrão dessas mensagens é de 1s. Durante a convergência, esse tempo é reduzido
pela metade
![]() Durante
a convergência, os nós continuam aceitando requisições normalmente
Durante
a convergência, os nós continuam aceitando requisições normalmente
![]() Uma
expansão do cluster pode afetar as sessões existentes pois
nesse momento os clientes são remapeados pelos nós do
cluster
Uma
expansão do cluster pode afetar as sessões existentes pois
nesse momento os clientes são remapeados pelos nós do
cluster
Medida de
Performance do NLB
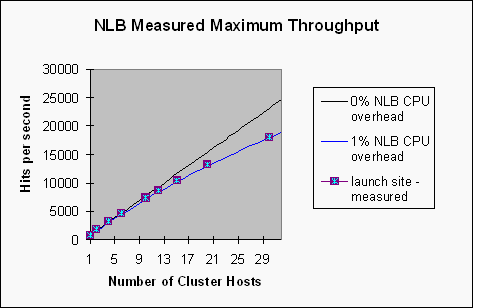
Escalabilidade de um Site - teste realizado sempre na
saturação do cluster.
O máximo atingido com 30 hosts
foram 18000 requisições GET/s
(400 Mbps ou 1,55b hits/dia)
Conclusões
![]() Foi
realizado um levantamento sobre as diversas formas propostas de balanceamento
de carga
Foi
realizado um levantamento sobre as diversas formas propostas de balanceamento
de carga
![]() Diversas
topologias de balanceamento foram demonstradas
Diversas
topologias de balanceamento foram demonstradas
![]() Alguns
dos algoritmos de escalonamento mais comumente usados foram comentados
Alguns
dos algoritmos de escalonamento mais comumente usados foram comentados
![]() A
escalabilidade, disponibilidade e aplicabilidade de cada abordagem foi apontada
A
escalabilidade, disponibilidade e aplicabilidade de cada abordagem foi apontada
![]() Um
estudo de caso foi colocado a fim de demonstrar a relevância do tema
Um
estudo de caso foi colocado a fim de demonstrar a relevância do tema
Bibliografia
![]() Valeria Cardellini,
Michele Colajanni, Philip
Valeria Cardellini,
Michele Colajanni, Philip
![]() Richard
B. Bunt, Derek L. Eager, Gregory M. Oster, and Carey
L. Williamson; Achieving Load Balance and Effective Caching in
Clustered Web Servers
Richard
B. Bunt, Derek L. Eager, Gregory M. Oster, and Carey
L. Williamson; Achieving Load Balance and Effective Caching in
Clustered Web Servers
![]() Yong
Meng TEO, Rassul AYANI; Comparison of Load Balancing
Strategies on Cluster-based Web Servers
Yong
Meng TEO, Rassul AYANI; Comparison of Load Balancing
Strategies on Cluster-based Web Servers
![]() Valeria Cardellini,
Michele Colajanni, Philip S. Yu; Geographic Load Balancing
for Scalable Distributed Web Systems
Valeria Cardellini,
Michele Colajanni, Philip S. Yu; Geographic Load Balancing
for Scalable Distributed Web Systems
![]() Vivek
Viswanathan; Load
Balancing Web Applications ( http://www.onjava.com/pub/a/onjava/2001/09/26/load.html)
Vivek
Viswanathan; Load
Balancing Web Applications ( http://www.onjava.com/pub/a/onjava/2001/09/26/load.html)
![]() http://www.microsoft.com/technet/winnt/winntas/technote/crhasite.asp
http://www.microsoft.com/technet/winnt/winntas/technote/crhasite.asp
![]() http://www.microsoft.com/windows2000/library/howitworks/cluster/introcluster.asp
http://www.microsoft.com/windows2000/library/howitworks/cluster/introcluster.asp
![]() http://www.microsoft.com/technet/acs/clbovrvw.asp
http://www.microsoft.com/technet/acs/clbovrvw.asp