|
|
 |
HTTP
|
 |
|
|
|
|
HTTP
|
|
|
História
 O primeiro browser! |
Em 1990, Tim Bernard-Lee escreveu o primeiro cliente e primeiro servidor web. Assim surgia o HTML e o HTTP, surgia a WWW e todo o universo que nos trouxe. Tim escreveu em 1991 as razões pelas quais criar um novo protocolo (o HTTP), e comentava que os até então existentes não atendiam às necessidades da comunidade científica. |
Por exemplo, os protocolos de e-mails permitiam apenas mensagens de um autor para um pequeno número de destinatários; os protocolos de arquivo permitiam a transferência de dados sob o pedido do transmissor ou do receptor, mas com pouca capacidade de processamento; protocolos de notícias ainda permitiam o envio de informação massiva, e o mais interessante eram os protocolos de busca, que permitiam acesso a documentos após as buscas, mas poucos eram os que existiam.
O protocolo necessitado para acesso a informação deveria atender aos seguintes requisitos:
- Incorporação da funcionalidade
do FTP;
- Habilidade de requisitar uma busca;
- Negociação automática de formato;
- Habilidade para, do cliente, referenciar outro servidor.
Como funciona?
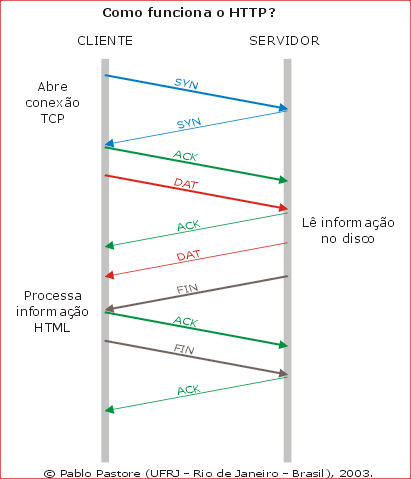 |
O navegador não pode ler o documento do disco de destino diretamente, então este necessita estar rodando um "servidor web". Um "servidor web" basicamente é um programa que escuta os pedidos dos navegadores e os executa. Pedido HTTP O navegador começa abrindo uma conexão TCP com o servidor (SYN). |
O passo seguinte é então
o navegador mandar o pedido para o servidor (DAT). Ele o faz enviando uma mensagem
no seguinte formato:
GET [diretório(URI)] [HTTP/versão]
Resposta HTTP
O servidor localiza o documento e manda a seguinte resposta (DAT):
HTTP/[ver] [código] [texto]
Campo1: valor1
Campo2: valor2
... conteúdo do documento....
Explicando os termos acima: ver é a versão do HTTP, código é um número de 3 algarismos, geralmente 200 para dizer que está tudo OK, e depois um texto que traduz o signficado deste número para uma linguagem conhecida (geralmente é o próprio "ok"). Seguem-se algumas informações usadas pelo cabeçalho, como data, tamanho do arquivo etc. Depois de uma linha em branco, vem a informação do documento propriamente.
Exemplo de cabeçalho:
| HTTP/1.0 200 OK Server: Netscape-Communications/1.1 Date: Tuesday, 25-Nov-99 01:22:03 GMT Last-modified: Thursday, 20-Nov-99 10:44:33 GMT Content-length: 6372 Content-type: text/html <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <HTML> ... conteúdo do documento ... |
Os campos exemplificados são de fácil compreensão. Chamo a atenção para o chamado "content-type", que tem como valor "text/html". Este campo é o que permite ao navegador saber que tipo de documento está sendo trafegado, e, dependendo do tipo, abri-lo na própria janela, ou chamar um outro programa para fazê-lo. Outros exemplos de tipos de documento são: "text/plain" (texto puro), "image/gif" (imagem do tipo gif), "image/jpg" entre outros.
Alguns documentos são abertos dentro de próprio documento html, como é o caso das imagens. Outros são visualizados também dentro do documento html, mas quererem um plug-in, como é o caso das animações "flash" (da Macromedia).
Um importante conceito aqui é que para o navegador não importa como o servidor produz a informação que lhe manda. Portanto, esta pode ser estática, pode ser dinâmica, pode ser gerada por um programa (cgi), processada de mil e uma maneiras, que ele não vai saber: só o que importa é saber o tipo de documento, e usar o programa ou plug-in necessário para abri-lo.
Códigos de estado do servidor
Acima vimos o exemplo do código de estado "OK", mas é interessante conhecermos os possíveis códigos que o servidor pode retornar:
| 1xx | Não utilizado. Reservado para testes. |
| 2xx | O pedido foi atendido corretamente. |
| 200 | OK: o servidor fez exatamente o que o cliente queria. |
| outros | Geralmente usados no procesamento de scripts, muito raros. |
| 3xx | O recurso está em algum outro lugar e o cliente deve tentar de novo em um novo endereço. |
| 301 | Movido permanentemente. |
| 302 | Movido temporariamente (os enlaces não necessitam ser modificados). |
| 304 | Não modificado. Usado quando o cliente utiliza o cabeçalho "se-modificado-desde" e o recurso não foi modificado desde o tempo apontado. Significa que a versão do documento em cache deve ser exibida. |
| 4xx | O cliente de alguma maneira se equivocou, geralmente pedindo por algo que não deveria ter pedido. |
| 400 | Pedido errado. O pedido não tem a sintaxe correta. |
| 401 | Não autorizado. O cliente não está autorizado a acessar o recurso. Pode mudar se o cliente tenta de novo com um cabeçalho de autorização. |
| 403 | Proibido. O cliente não pode acessar o recurso e uma autorização não vai ajudar em nada. |
| 404 | Não encontrado. O mais conhecido. Significa que o servidor não tem nem idéia sobre o paradeiro deste recurso e não tem nada a informar. |
| 5xx | Significa que o servidor se equivocou ou que não pôde atender ao pedido do cliente. |
| 500 | Erro interno do servidor. Alguma coisa aconteceu de errado no servidor. |
| 501 | Não implementado. O método de pedido não é suportado pelo servidor. |
| 503 | Serviço não disponível. Acontece algumas vezes quando o servidor está muito ocupado e não pode atender ao pedido. Geralmente a solução é esperar um tempo e tentar de novo. |
Versões do HTTP
| HTTP/0.9 | Muito primitiva... na verdade nunca foi especificada em nenhum padrão. |
| HTTP/1.0 | É a correção da anterior. Foi publicada como padrão no RFC 1945. Foi a versão mais utilizada durante certo tempo, dando espaço hoje para a versão 1.1. |
| HTTP/1.1 | Descrito na RFC 2068. Extende e melhora a versão 1.0 em certas áreas. É suportada pela maioria dos navegadores, inclusive o Internet Explorer 6.0.. |
As maiores vantagens da versão 1.1 são as extensões para autorização de documentos online via HTTP e um mecanismo que permite que após o pedido do cliente a conexão se mantenha aberta, o que evita ter que abrir uma nova conexão para o seguinte pedido. Isso é vantajoso porque agiliza a abertura de documentos que tenham outros arquivos associados.
|
|
|
|
|
Última
atualização em 7 de julho de 2003.
(c) Pablo Pastore, 2003.